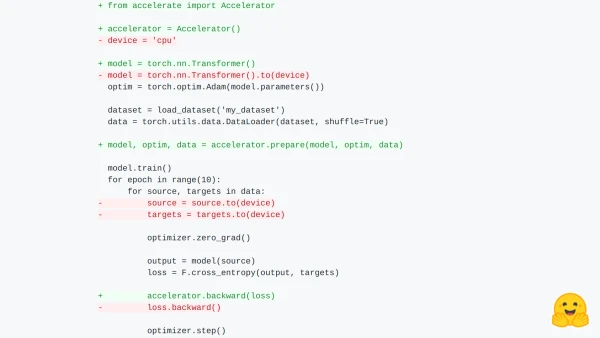
Hugging Face has launched 🤗 Accelerate, a library that lets PyTorch users run their custom training scripts on any device—CPU, single GPU, multi-GPU, or TPU—while maintaining full control over the training loop. By adding just a few lines of code, developers can enable distributed training and mixed precision without the usual boilerplate.
The core of Accelerate is the Accelerator class, which handles device placement, model wrapping, optimizer preparation, and dataloader synchronization. For example, a standard training loop can be adapted by:
- Creating an
Acceleratorobject. - Preparing the model, optimizer, and dataloader with
accelerator.prepare(). - Replacing
loss.backward()withaccelerator.backward(loss).
This approach eliminates the need for manual DistributedDataParallel wrapping, DistributedSampler setup, or device-aware data loading. The library also provides a launcher command to run scripts on various configurations without code changes.
Accelerate currently supports mixed precision (FP16) and plans to integrate with FairScale, DeepSpeed, and AWS SageMaker. Users can force CPU or FP16 training via initialization arguments or the launcher.
For saving models, use accelerator.unwrap_model(model) to access the underlying model. The library also synchronizes random number generators across processes for reproducibility.
Accelerate is available now on GitHub and Hugging Face. The team encourages community contributions and feedback.