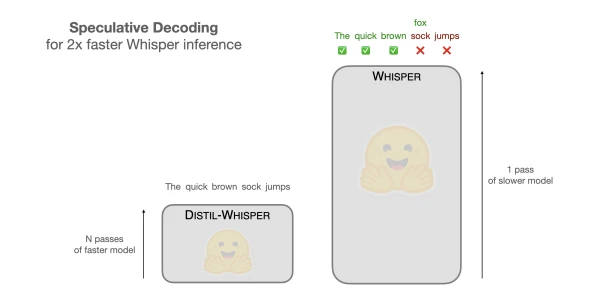
Researchers have introduced a novel technique called speculative decoding that can double the inference speed of OpenAI's Whisper speech recognition model without sacrificing accuracy. This method leverages a smaller, faster draft model to generate candidate outputs, which are then validated by the larger Whisper model in parallel. By reducing the number of sequential decoding steps, speculative decoding achieves up to 2× speedup on various hardware, making real-time transcription more accessible. The approach is compatible with existing Whisper models and requires no additional training.
Accelerate Whisper Speech Recognition with Speculative Decoding
AI
April 26, 2026 · 4:37 PM