Transformer-based models like BERT have revolutionized NLP, but their quadratic attention mechanism—$O(n^2)$ in time and memory—makes them impractical for sequences longer than 512 tokens. BigBird, introduced in a 2020 paper, overcomes this limitation with block sparse attention, enabling processing of sequences up to 4096 tokens at a fraction of the cost.
Why Approximate Attention?
Full attention, where every token attends to all others, is computationally prohibitive for long documents. BigBird instead approximates this by selecting a subset of key tokens for each query. The key insight is that not all interactions are equally important; nearby tokens and a few strategically chosen distant tokens suffice.
Three Attention Mechanisms
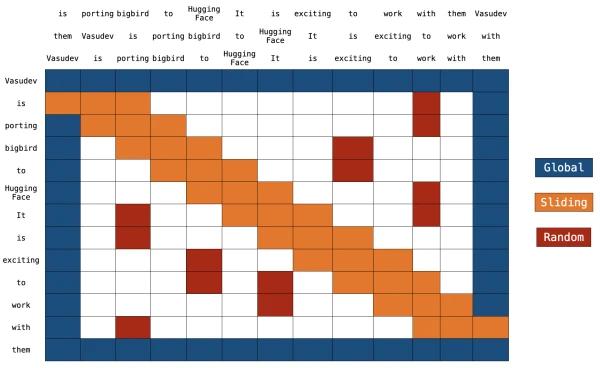
BigBird combines three complementary attention patterns:
- Global Attention: A few tokens (e.g.,
[CLS]) attend to all tokens and vice versa, preserving long-range context. - Sliding Attention: Each token attends to a fixed-size window of neighbors (e.g., 3 tokens left and right), capturing local dependencies.
- Random Attention: Each token attends to a small random set of other tokens, ensuring connectivity across the entire sequence.
This combination achieves linear complexity $O(n)$ while maintaining performance close to full attention.
Implementation Details
BigBird's block sparse attention is implemented efficiently by dividing tokens into blocks and using masked matrices. For example, with a sequence length of 4096 and block size 64, the effective attention matrix becomes sparse, with only $O(n)$ non-zero entries. This drastically reduces memory and computation.
ITC vs. ETC
BigBird supports two configurations:
- ITC (Internal Transformer Construction): Adds global tokens within the input sequence.
- ETC (Extended Transformer Construction): Uses additional global tokens appended externally. ITC is simpler, while ETC offers more flexibility for tasks like question answering.
Using BigBird in 🤗 Transformers
BigBird RoBERTa-like models are now available in the 🤗 Transformers library. You can load them with:
from transformers import BigBirdModel
model = BigBirdModel.from_pretrained('google/bigbird-roberta-base')
The model handles sequences up to 4096 tokens, making it ideal for long-document summarization, QA, and other tasks where context is key.
Conclusion
BigBird's block sparse attention offers an efficient approximation to full attention, enabling transformers to scale to longer sequences without sacrificing performance. It is a practical tool for applications involving lengthy texts.