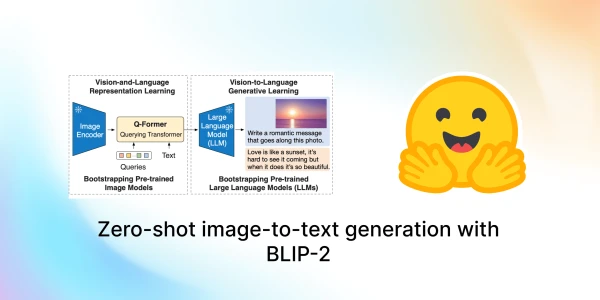
Salesforce Research has introduced BLIP-2, a new paradigm for vision-language models that achieves state-of-the-art performance while dramatically reducing training costs. The key innovation is a lightweight Querying Transformer (Q-Former) that bridges the gap between frozen pre-trained image encoders and large language models, eliminating the need for expensive end-to-end training.
BLIP-2 can tackle a range of image-to-text tasks, including image captioning, visual question answering, and chat-based prompting. By leveraging existing powerful models like ViT for vision and OPT or Flan T5 for language, it keeps the computational burden low—only the Q-Former is trainable. This efficiency paves the way for multimodal AI systems similar to ChatGPT.
Now available in Hugging Face Transformers, BLIP-2 is easy to use. Users can install the latest Transformers from source, load a pre-trained model, and apply it to their own images. For example, a New Yorker cartoon can be fed into the model to generate captions or answer questions.
This approach not only democratizes access to advanced multimodal AI but also hints at a future where combining vision and language models becomes as simple as plugging in components.