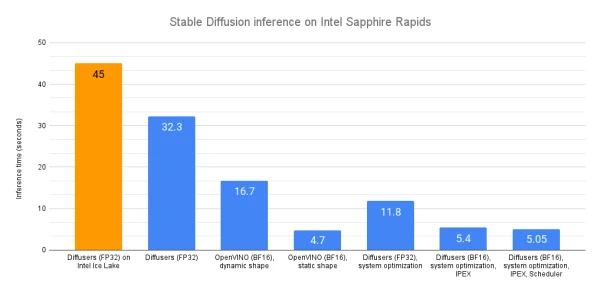
This article explores techniques to accelerate Stable Diffusion inference on Intel's latest Xeon Sapphire Rapids CPUs. Using the Diffusers library, default float32 inference on a Sapphire Rapids server yields an average latency of 32.3 seconds per image—a significant improvement over the 45 seconds on previous-generation Ice Lake CPUs.
The first major speedup comes from OpenVINO, Intel's open-source inference optimization toolkit. By replacing the standard StableDiffusionPipeline with OVStableDiffusionPipeline, the model is automatically converted to OpenVINO format and optimized for bfloat16, cutting latency to 16.7 seconds—a 2x improvement. Additionally, reshaping the pipeline to a fixed output resolution (e.g., 512x512) unlocks static shapes, further reducing latency to just 4.7 seconds, an additional 3.5x speedup. Combined, OpenVINO with Sapphire Rapids delivers nearly 10x faster inference compared to vanilla Ice Lake.
For those unable to use OpenVINO, system-level optimizations offer alternatives. Installing a high-performance memory allocator like jemalloc and leveraging Intel's OpenMP runtime (libiomp) can enhance memory and parallel processing. Other methods include using Intel Extension for PyTorch (IPEX) with BF16 mixed precision, which reduces latency to 11.8 seconds, and experimenting with different schedulers (e.g., DPMSolverMultistepScheduler) to cut inference steps while maintaining quality.
The article concludes that OpenVINO provides the most significant gains, but even without it, combining IPEX and memory optimizations yields substantial improvements. Future posts will cover distributed fine-tuning on the same hardware.