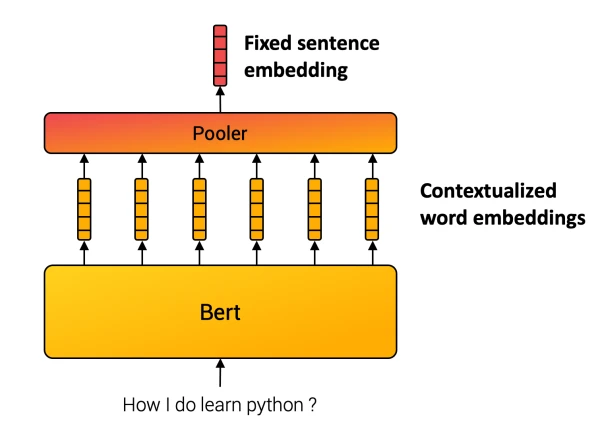
Sentence embedding is a technique that maps sentences to vectors of real numbers, capturing semantic meaning for downstream tasks like clustering, text mining, and question answering.
As part of the project "Train the Best Sentence Embedding Model Ever with 1B Training Pairs," conducted during Hugging Face's Community Week using JAX/Flax, we developed state-of-the-art sentence embedding models. The project leveraged 7 TPUs v3-8 and guidance from Google's Flax, JAX, and Cloud team members.
Training Methodology
Model
Unlike words, sentences lack a finite set. Sentence embedding methods compose inner words into a final representation. For instance, the SentenceBERT model uses a Transformer followed by a pooling operation over contextualized word vectors.
Multiple Negative Ranking Loss
We used a contrastive training method with a dataset of sentence pairs (a_i, p_i) that share close meaning, such as (query, answer-passage) or (question, duplicate question). The model is trained to map paired sentences to nearby vectors and unpaired ones to distant vectors. This is known as training with in-batch negatives, InfoNCE, or NTXentLoss.
Formally, given a batch of n samples, the model optimizes the loss:
-1/n * sum_{i=1}^n exp(sim(a_i, p_i)) / sum_j exp(sim(a_i, p_j))
where sim is a similarity function (Cosine-Similarity or Dot-Product). We used a scaled similarity with factor C=20 to increase score differences.
Improving Quality with Better Batches
Batch composition is key. We focused on three aspects:
- Size matters: Larger batch sizes improve performance in contrastive learning.
- Hard negatives: Including examples that are difficult to distinguish from positive pairs enhances learning.
- Cross-dataset batches: Mixing samples from multiple datasets within a batch helps learn global structure across topics.
Training Infrastructure and Data
The project benefited from efficient hardware, specifically TPUs developed by Google, which excel at matrix multiplications. TPUs have specific code requirements but provide substantial computational power.
The combination of large-scale data, careful batch design, and powerful infrastructure led to models that achieve strong performance on various sentence embedding benchmarks.