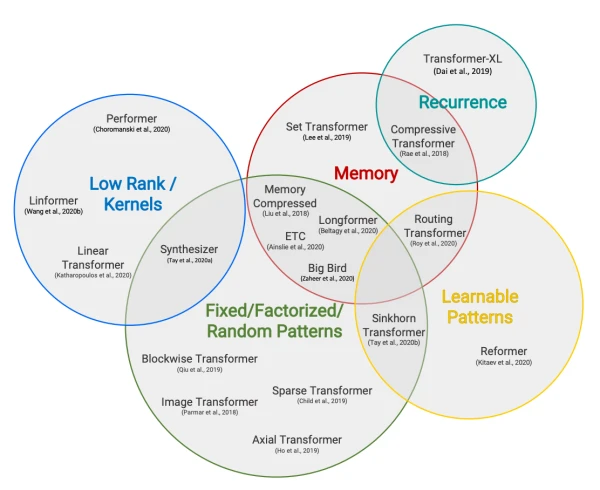
In early 2021, the Hugging Face reading group examined four influential papers addressing the quadratic memory and time cost of transformer models with respect to sequence length. This blog post summarizes the key ideas and findings from that discussion.
The Problem: Quadratic Complexity of Self-Attention
Standard transformer self-attention scales quadratically with input sequence length, limiting practical use to sequences of 512-1024 tokens. In 2020, researchers proposed several methods to break this barrier, allowing transformers to handle long documents, code, or scientific texts efficiently.
Four Approaches to Long-Range Attention
-
Custom Attention Patterns: Longformer
- Replaces full self-attention with a combination of windowed local attention and global attention on a few tokens.
- Scales linearly with sequence length and serves as a drop-in replacement for standard attention.
- Achieves strong results on document-level NLP tasks without costly long-range pre-training.
-
Recurrence: Compressive Transformer
- Extends Transformer-XL by compressing past hidden states into compressed memories.
- Maintains access to a longer history without quadratic memory growth.
- Useful for modeling long sequences such as text or audio.
-
Low-Rank Approximations: Linformer
- Projects keys and values to lower dimensions, reducing self-attention complexity from O(n²) to O(n).
- Empirically shows that self-attention matrices are low-rank, enabling this approximation.
- Retains competitive performance on standard benchmarks.
-
Kernel Approximations: Performer
- Uses the FAVOR+ algorithm to approximate softmax attention via random features.
- Achieves linear time and memory complexity while preserving differentiability.
- Provides theoretical guarantees and matches full-attention accuracy on multiple tasks.
Common Trends and Takeaways
- All methods reduce complexity from quadratic to linear (or near-linear) in sequence length.
- Most can fine-tune pre-existing models without full pre-training from scratch.
- The choice of approach depends on the task; for example, Longformer excels at document QA, while Performer is general-purpose and theoretically grounded.
The field continues to evolve, with newer models like BigBird and Sparse Transformers building on these ideas. For a comprehensive survey, see Efficient Transformers: A Survey and the Long Range Arena benchmark.