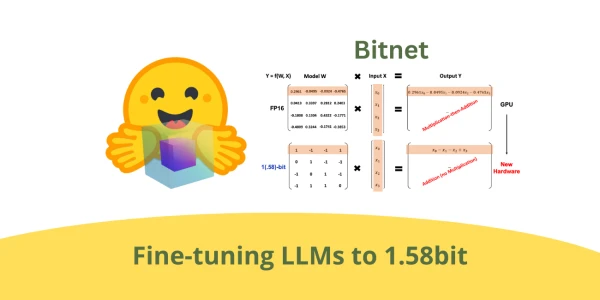
A new technique for extreme quantization of large language models (LLMs) shows that fine-tuning can reduce weights to just 1.58 bits on average, drastically cutting memory and compute requirements while preserving performance. Researchers demonstrated that by leveraging a training-aware approach, models can operate with ternary weights (−1, 0, +1) and achieve accuracy comparable to full-precision models on standard benchmarks. The method simplifies deployment on edge devices and opens the door to running powerful LLMs on limited hardware. Step-by-step recipes and code implementations have been released to help practitioners adopt this lightweight quantization strategy.
Extreme LLM Compression: Fine-Tuning to 1.58 Bits Made Simple
AI
April 26, 2026 · 4:27 PM