Diffusion models have become a cornerstone of generative AI, known for creating photorealistic images from text prompts. Enterprises now leverage them for synthetic data generation and content creation. The Hugging Face hub offers over 5,000 pre-trained text-to-image models, and the Diffusers library simplifies building image generation workflows.
Like Transformer models, Diffusion models can be fine-tuned for specific business needs. While traditionally limited to GPUs, Intel's 4th Gen Xeon CPUs (Sapphire Rapids) with Advanced Matrix Extensions (AMX) now enable efficient fine-tuning on CPUs. This post demonstrates fine-tuning a Stable Diffusion model using textual inversion with just five example images on an Intel Sapphire Rapids cluster.
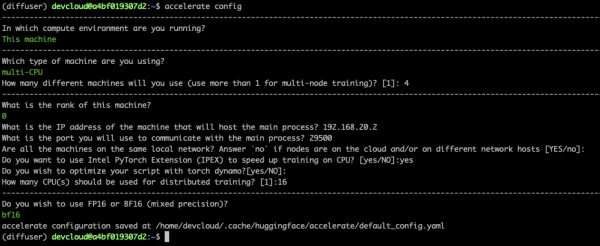
Setting Up the Cluster
Intel provided four servers on the Intel Developer Cloud (IDC). Each server features two 56-core Sapphire Rapids CPUs (224 threads total). Configure password-less SSH between nodes and create a conda environment with dependencies including Intel oneCCL for distributed communication and Intel Extension for PyTorch (IPEX) for hardware acceleration.
conda create -n diffuser python==3.9
conda activate diffuser
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip3 install transformers accelerate==0.19.0
pip3 install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install intel_extension_for_pytorch
conda install gperftools -c conda-forge -y
Clone the diffusers repository and install from source. Modify the textual inversion script to import IPEX and optimize the U-Net and VAE models.
Fine-Tuning the Model
The fine-tuning process uses textual inversion, which embeds a new concept into the model's text encoder using a few images. This method is efficient and requires minimal data.
After setting up the environment and applying the IPEX optimizations, run the training script distributed across nodes. The training converges quickly due to the hardware acceleration.
Generating Images with the Fine-Tuned Model
Once fine-tuned, generate images using prompts containing the learned concept. The model produces high-quality images aligned with the training data.
Troubleshooting
Common issues include memory allocation errors and network timeouts. Ensure libtcmalloc is installed and check firewall settings between nodes.
Conclusion
Intel Sapphire Rapids CPUs with AMX make fine-tuning Stable Diffusion models practical on CPU clusters. This opens up new possibilities for organizations without GPU access. The full code and instructions are available on GitHub.