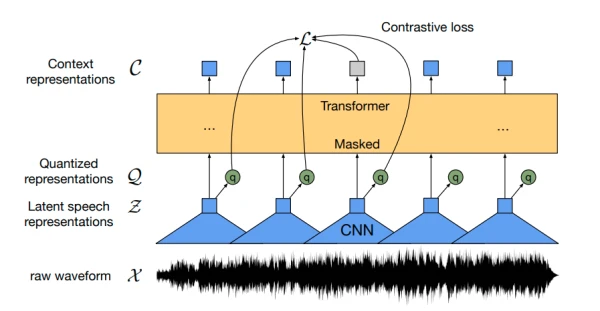
Wav2Vec2, a pretrained model for Automatic Speech Recognition (ASR) released in September 2020 by Alexei Baevski, Michael Auli, and Alex Conneau, learns powerful speech representations from over 50,000 hours of unlabeled speech using a contrastive pretraining objective. Similar to BERT's masked language modeling, it creates contextualized speech representations by randomly masking feature vectors before passing them to a transformer network.
For the first time, pretraining followed by fine-tuning on very little labeled speech data yields competitive results to state-of-the-art ASR systems. With just 10 minutes of labeled data, Wav2Vec2 achieves a word error rate (WER) of less than 5% on the clean LibriSpeech test set.
This guide explains how to fine-tune Wav2Vec2 pretrained checkpoints on any English ASR dataset, using Connectionist Temporal Classification (CTC) without a language model. For demonstration, we fine-tune the "base" checkpoint on the small Timit dataset (5 hours of training data).
CTC is an algorithm for training neural networks in sequence-to-sequence problems, especially ASR and handwriting recognition. I recommend reading the blog post "Sequence Modeling with CTC (2017)" by Awni Hannun.
First, install the required packages:
!pip install datasets>=1.18.3
!pip install transformers==4.11.3
!pip install librosa
!pip install jiwer
To avoid losing checkpoints, upload them directly to the Hugging Face Hub by logging in:
from huggingface_hub import notebook_login
notebook_login()
Also install Git-LFS:
!apt install git-lfs
Prepare Data, Tokenizer, and Feature Extractor
ASR models need a feature extractor for speech signal processing and a tokenizer for output decoding. In Hugging Face Transformers, Wav2Vec2 uses Wav2Vec2CTCTokenizer and Wav2Vec2FeatureExtractor.
Create Wav2Vec2CTCTokenizer
The pretrained checkpoint maps speech to context representations. A fine-tuned model adds a linear layer on top for classification. The output size corresponds to the vocabulary of the labeled dataset. Let's examine the Timit dataset:
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
print(timit)
Output:
DatasetDict({
train: Dataset({ features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'], num_rows: 4620 })
test: Dataset({ features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'], num_rows: 1680 })
})
We only need the text transcriptions, so remove unneeded columns:
timit = timit.remove_columns(["phonetic_detail", "word_detail", "dialect_region", "id", "sentence_type", "speaker_id"])
Display random samples to understand the transcriptions:
def show_random_elements(dataset, num_examples=10):
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file", "audio"]))
(Note: Timit is typically evaluated using phoneme error rate, but WER is more common in ASR. We use WER for generality.)