
Introduction
Diffusion models like DALL-E 2 and Stable Diffusion are powerful generative tools, but their outputs don't always match human preferences. The alignment problem—ensuring model outputs reflect human values such as quality or intent—is a key challenge. Reinforcement Learning (RL) offers a solution, as seen in ChatGPT's RLHF training.
In a recent paper, Training Diffusion Models with Reinforcement Learning, Black et al. introduce Denoising Diffusion Policy Optimization (DDPO), a method to fine-tune diffusion models using RL. This post explains DDPO, how it works, and how to apply it to Stable Diffusion using the DDPOTrainer from the trl library.
The Advantages of DDPO
Before DDPO, Reward-Weighted Regression (RWR) was common for RL fine-tuning. RWR uses the diffusion model's denoising loss with per-sample weighting based on rewards. However, RWR ignores intermediate denoising steps, leading to approximations that reduce performance on complex objectives.
DDPO models the entire denoising process as a multi-step Markov Decision Process (MDP), with a reward at the final step. This allows exact likelihood computation for each denoising step, avoiding accumulated errors. The result is more efficient and accurate optimization.
DDPO Algorithm Briefly
DDPO uses Proximal Policy Optimization (PPO) within the MDP framework. The key adaptation is in trajectory collection during PPO. The diagram below summarizes the flow:
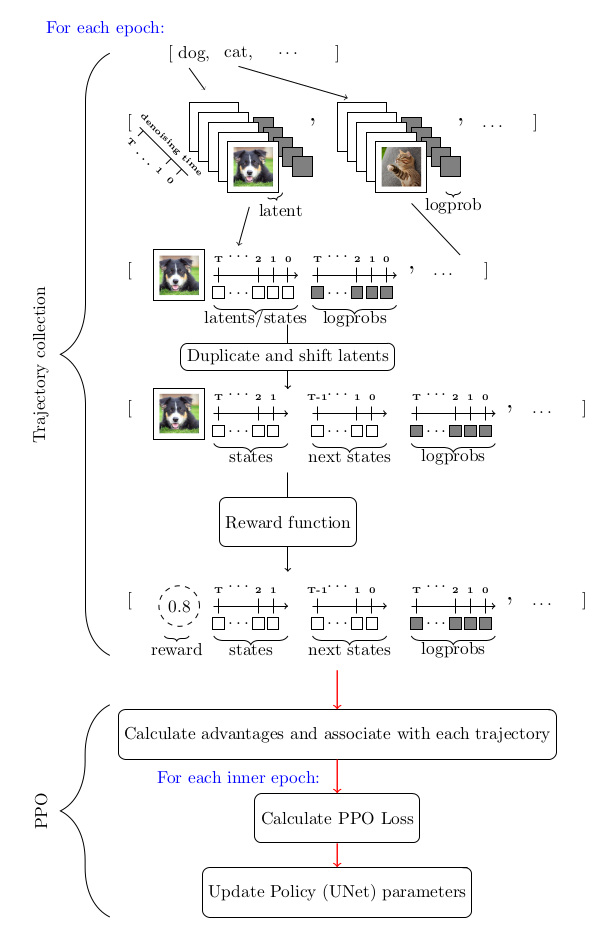
DDPO and RLHF: Enforcing Aesthetic Quality
Standard RLHF involves supervised fine-tuning, reward model training, and RL fine-tuning. With DDPO, the workflow simplifies to:
- Start with a pretrained diffusion model.
- Train a reward model using preference data.
- Fine-tune with DDPO using the reward model.
To improve aesthetic quality, we:
- Use a pretrained Stable Diffusion model.
- Train a CLIP model with a regression head on the AVA dataset to predict human aesthetic ratings.
- Fine-tune Stable Diffusion with DDPO using the aesthetic predictor as reward.
Training Stable Diffusion with DDPO
Setup
You need at least an A100 NVIDIA GPU (or equivalent) to avoid out-of-memory errors. Install the required libraries:
pip install trl[diffusers]
For logging and image tracking:
pip install wandb torchvision
Alternatively, use TensorBoard instead of wandb.
A Walkthrough
The trl library provides the DDPOTrainer class. The training loop involves:
- Generating images with the current model.
- Computing rewards using the aesthetic predictor.
- Updating the model via PPO with DDPO loss.
The trainer handles trajectory collection, reward calculation, and optimization automatically. Below is a simplified example:
from trl import DDPOTrainer
trainer = DDPOTrainer(
model_id="CompVis/stable-diffusion-v1-4",
reward_model_id="your-aesthetic-model",
train_batch_size=8,
sample_batch_size=4,
...
)
trainer.train()
For full details, refer to the original paper and the blog post.