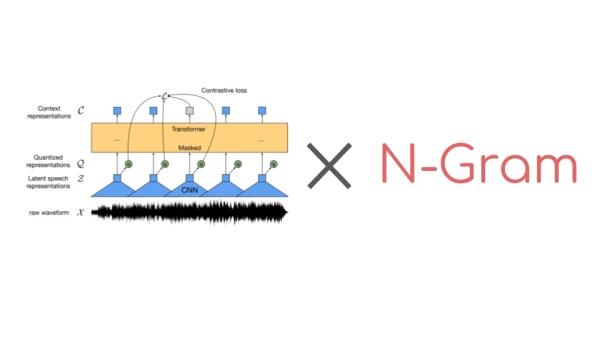
Wav2Vec2, a pre-trained model for speech recognition introduced by Meta AI in September 2020, has become a cornerstone for self-supervised learning in the field. Its popularity on the Hugging Face Hub is evident, with the most popular checkpoint seeing over 250,000 monthly downloads. While Wav2Vec2 can produce decent transcriptions without an external language model, combining it with an n-gram language model can significantly boost accuracy, especially when training data is limited.
Until recently, Hugging Face Transformers lacked a simple interface for decoding audio with a language model. Now, with integration with Kensho Technologies' pyctcdecode library, users can easily combine Wav2Vec2 with an n-gram language model. This guide walks through the process: understanding the decoding difference, acquiring suitable data, building an n-gram with KenLM, and integrating it with a fine-tuned Wav2Vec2 checkpoint.
1. Decoding Audio with and without a Language Model
Without a language model, transcription often produces phonetically correct but misspelled words. For example, using facebook/wav2vec2-base-100h on a LibriSpeech sample yields 'christmaus' instead of 'christmas'. Adding an n-gram language model corrects such errors by considering word probabilities.
2. Getting Data for Your Language Model
To build an n-gram model, you need a text corpus representative of the target domain. For English, the LibriSpeech corpus transcriptions or any large text dataset can be used.
3. Building an N-Gram with KenLM
KenLM is a fast language model toolkit. A 4-gram model is a common choice. The command-line tool creates an ARPA file, which can be converted to a binary format for faster loading.
4. Combining the N-Gram with Wav2Vec2
With pyctcdecode, you can create a decoder that uses the language model. The Wav2Vec2ProcessorWithLM class in Transformers simplifies this. After loading the processor and model, decoding with the language model improves transcription accuracy, correcting errors like 'christmaus' to 'christmas'.
For a detailed code walkthrough, refer to the official blog post and Colab notebook. This integration opens up better speech recognition for many applications.