In a follow-up to our earlier exploration of Intel's 4th-gen Xeon Sapphire Rapids CPUs, we now turn to inference. Using popular HuggingFace transformers with PyTorch, we benchmark performance on both short and long NLP token sequences, comparing Ice Lake and Sapphire Rapids servers with the latest Optimum Intel library.
Why CPU-Based Inference?
Choosing between CPU and GPU for deep learning inference depends on model size, parallelism, and cost. Smaller models run efficiently on CPUs, while larger models may benefit from GPU power. CPUs offer cost-effective, scalable deployment, especially when ultra-low latency isn't critical.
Test Setup
We used Amazon EC2 instances:
- c6i.16xlarge (Ice Lake)
- r7iz.16xlarge-metal (Sapphire Rapids)
Both have 32 physical cores (64 vCPUs). Setup included Ubuntu 22.04, PyTorch 1.13 with Intel Extension for PyTorch, Transformers 4.25.1, and Optimum Intel on the Sapphire Rapids instance.
Benchmarking NLP Models
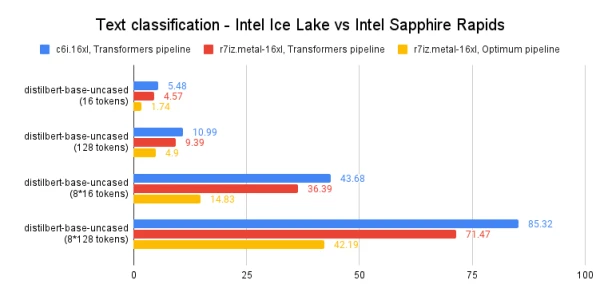
Models: distilbert-base-uncased, bert-base-uncased, roberta-base. We measured mean and p99 latency for single and batch inference with 16-token and 128-token sentences.
models = ["distilbert-base-uncased", "bert-base-uncased", "roberta-base"]
sentence_short = "This is a really nice pair of shoes, I am completely satisfied with my purchase"
sentence_long = "These Adidas Lite Racer shoes hit a nice sweet spot..."
sentence_short_array = [sentence_short] * 8
sentence_long_array = [sentence_long] * 8
Benchmark function with warmup and 1,000 iterations:
import time
import numpy as np
def benchmark(pipeline, data, iterations=1000):
for i in range(100):
result = pipeline(data)
times = []
for i in range(iterations):
tick = time.time()
result = pipeline(data)
tock = time.time()
times.append(tock - tick)
return "{:.2f}".format(np.mean(times) * 1000), "{:.2f}".format(np.percentile(times, 99) * 1000)
On Ice Lake, we used vanilla Transformers pipeline; on Sapphire Rapids, we leveraged Optimum Intel for additional optimizations.
Full results demonstrate significant latency reductions with Sapphire Rapids and AMX instructions, making CPU inference a compelling option for many NLP workloads.