This guide introduces Mask2Former and OneFormer, two state-of-the-art neural networks for image segmentation, now available in the 🤗 Transformers library. These models unify the three main segmentation tasks—instance, semantic, and panoptic—under a single architecture.
Image Segmentation
Image segmentation involves partitioning an image into meaningful segments, such as people or cars. It is broadly divided into three subtasks:
- Instance segmentation: Identifies individual object instances (e.g., each person) and outputs a binary mask and class label per instance. Instances can overlap.
- Semantic segmentation: Assigns a class label to every pixel (e.g., "person" or "sky") without distinguishing between instances of the same class. No overlap is allowed.
- Panoptic segmentation: Combines instance and semantic segmentation by segmenting both "things" (countable objects) and "stuff" (uncountable regions) into non-overlapping segments with binary masks and class labels.
Universal Image Segmentation
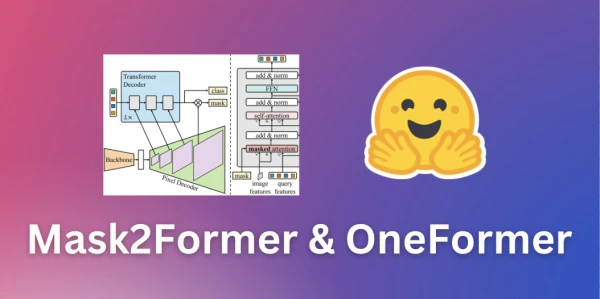
Since 2020, models like DETR, MaskFormer, and now Mask2Former have adopted a unified "mask classification" paradigm, replacing the traditional per-pixel classification for semantic segmentation. Mask2Former improves upon its predecessors by enhancing the architecture to handle instance segmentation as well. It uses a backbone (ResNet or Swin Transformer) to extract features, a pixel decoder to refine them, and a Transformer decoder to produce binary masks and class predictions.
OneFormer takes this further by achieving state-of-the-art on all three tasks after training solely on a panoptic dataset. It adds a text encoder that conditions the model on the desired task (instance, semantic, or panoptic), making it more accurate but slower than Mask2Former. Both models are available in 🤗 Transformers.
Inference with Mask2Former and OneFormer
Using these models is straightforward. Instantiate a pretrained checkpoint and processor from the Hugging Face Hub. For example, to load a Mask2Former model trained on COCO panoptic segmentation:
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-tiny-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-tiny-coco-panoptic")
Process an image, run inference, and post-process the results to obtain segmentation masks.
Fine-tuning Mask2Former and OneFormer
Both models can be fine-tuned on custom datasets. The 🤗 Transformers library provides training scripts and examples. Fine-tuning follows standard practices: load a pretrained model, replace the last layer to match the number of classes, and train using a suitable loss (e.g., cross-entropy for semantic segmentation).
Conclusion
Mask2Former and OneFormer represent a paradigm shift in image segmentation, enabling a single model to handle all segmentation tasks. Their availability in 🤗 Transformers makes them accessible for both research and production use.