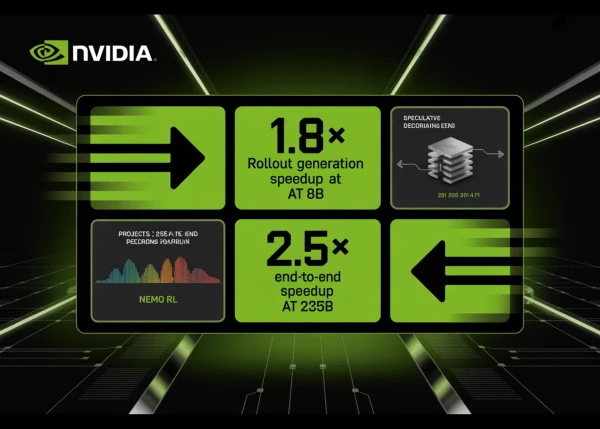
NVIDIA researchers have integrated speculative decoding directly into the NeMo RL training framework, achieving a 1.8× speedup in rollout generation for 8-billion-parameter models and projecting up to 2.5× end-to-end speedup for models as large as 235 billion parameters. The technique, now available in NeMo RL v0.6.0, accelerates reinforcement learning post-training without altering the target model's output distribution.
Rollout generation—where the model produces sample outputs for reward evaluation—constitutes 65–72% of total step time in RL training. By employing a smaller draft model to propose multiple tokens at once and using the target model to verify them via rejection sampling, speculative decoding maintains mathematical equivalence with autoregressive generation. This ensures no off-policy corrections or fidelity trade-offs.
In tests with Qwen3-8B under RL-Think (continuing training) and RL-Zero (learning from scratch), rollout generation emerged as the dominant bottleneck. The new method directly targets this stage, with log-probability recomputation and policy optimization occupying only 27–33% of step time. NeMo RL v0.6.0 also includes support for the SGLang backend, the Muon optimizer, and YaRN long-context training.
The research, detailed in a preprint on arXiv, demonstrates that speculative decoding offers a lossless acceleration mechanism for RL post-training, promising significant efficiency gains for large-scale model alignment tasks.