Hugging Face has launched Optimum, an open-source library designed to optimize the performance of Transformer models on specific hardware. The toolkit simplifies the complex process of model acceleration, making it accessible to engineers without specialized hardware expertise.
Scaling Transformer models for production is notoriously difficult. Companies like Tesla, Google, and Facebook run billions of predictions daily, but smaller teams lack the resources to optimize models for different hardware. Optimum bridges this gap by abstracting hardware-specific acceleration techniques, such as quantization and kernel optimization.
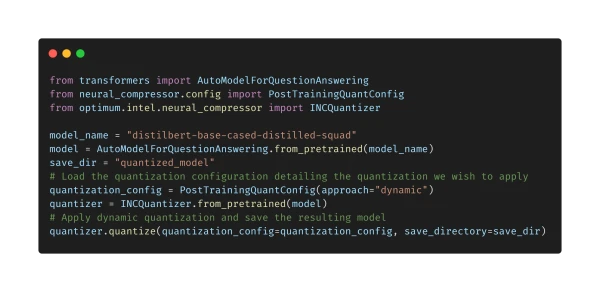
In a practical example, Optimum demonstrates how to quantize a model for Intel Xeon CPUs. Quantization reduces model size and speeds up inference, but it typically requires manual code changes and in-depth knowledge of the hardware. Optimum automates this process, integrating with Intel's Neural Compressor to deliver performance gains with minimal effort.
The library is the result of collaboration with hardware partners, starting with Intel. Hugging Face plans to expand Optimum's support to other hardware platforms, continuing its mission to democratize machine learning. Developers can follow the project on GitHub and contribute to its development.