Hugging Face Transformers has integrated Ray, a library for building scalable Python applications, into its Retrieval Augmented Generation (RAG) model. This update accelerates the document retrieval step by up to 2x and enhances scalability for distributed fine-tuning.
What Is Retrieval Augmented Generation (RAG)?
RAG is a seq2seq architecture that retrieves contextual documents from an external knowledge base, such as Wikipedia, during execution. These documents are combined with the input and passed to a generator, allowing the model to leverage both parametric knowledge and external information. This design achieves state-of-the-art results on knowledge-intensive tasks like question answering.
Scaling Up Fine-Tuning
The document retrieval component is crucial for RAG's performance but can become a bottleneck during data-parallel training. Earlier implementations used torch.distributed for retrieval, which had limitations: the rank-0 training worker had to handle all queries, creating a synchronization bottleneck, and the approach was tied to PyTorch.
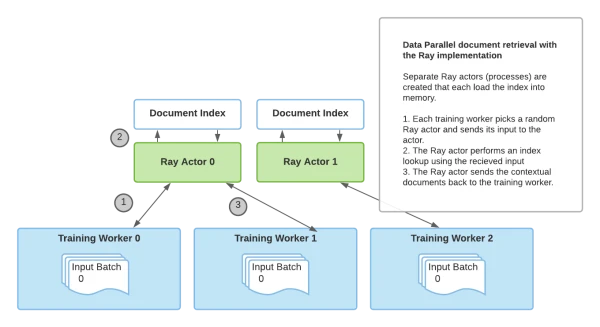
Ray for Document Retrieval
By leveraging Ray's stateful actor abstractions, the new implementation runs retrieval processes separately from training. Multiple Ray actors load the index and handle queries, eliminating the bottleneck and removing the dependency on PyTorch for retrieval.
Benchmarks show significant speedups: with 4 GPUs, Ray achieves 1.66 seconds per retrieval call versus 3.438 seconds with torch.distributed. Using more retrieval processes further improves performance as training scales.
How to Use It
Hugging Face provides a PyTorch Lightning-based fine-tuning script with an option for Ray retrieval. After installing Ray and Transformers, users can run the provided shell script to fine-tune RAG with distributed retrieval.
pip install ray
pip install transformers
pip install -r transformers/examples/research_projects/rag/requirements.txt
# Then run finetune-rag-ray.sh
This integration makes RAG training faster and more flexible, enabling researchers to scale up knowledge-intensive NLP models efficiently.