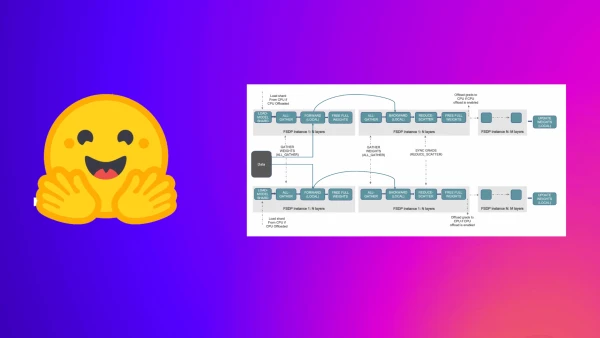
Training massive machine learning models is a challenge due to hardware limits. A new approach, PyTorch's Fully Sharded Data Parallel (FSDP) integrated with Hugging Face's Accelerate library, allows practitioners to train large models on limited GPU resources by sharding model states across devices.
Why This Matters
As models grow to billions of parameters, distributed training becomes essential. FSDP implements the Zero Redundancy Optimizer (ZeRO) stages: sharding optimizer states, gradients, and finally model parameters across GPUs. This contrasts with traditional Distributed Data Parallel (DDP), which replicates the entire model on each GPU, causing out-of-memory errors for large models.
Accelerate + FSDP: Zero Code Change
Hugging Face's Accelerate lets users adopt FSDP without modifying their code. The setup involves running accelerate config and selecting FSDP. The blog provides a causal language modeling example using GPT-2 Large (762M) and XL (1.5B) on two 24GB Titan RTX GPUs.
Performance Benchmarks
For GPT-2 Large, FSDP enabled batch sizes 2-3X larger than DDP, with CPU offload pushing even further. Training time was slightly slower than DDP+FP16 due to overhead, but FSDP's ability to fit larger batches can speed up dynamic batching tasks.
| Method | Max Batch Size | Training Time (min) |
|---|---|---|
| DDP | 7 | 15 |
| DDP+FP16 | 7 | 8 |
| FSDP (SHARD_GRAD_OP) | 11 | 11 |
| FSDP (FULL_SHARD) | 15 | 12-13 |
| FSDP + CPU Offload | 20-22 | 23-24 |
Handling 1.5B Parameters
GPT-2 XL (1.5B) caused OOM errors with DDP even at batch size 1. FSDP with CPU offload made training possible, though it required hours of compute. This illustrates FSDP's value for models that otherwise would not fit GPU memory.
The Bottom Line
FSDP is a practical solution for training large language models on modest hardware. While not always faster than DDP, it expands the feasible model size and batch size, making large-scale AI training more accessible.