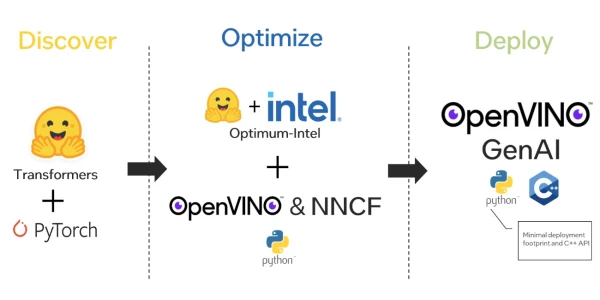
Intel, in collaboration with Hugging Face, has introduced Optimum-Intel, a tool designed to accelerate AI model optimization and deployment using OpenVINO GenAI. This integration simplifies the process of fine-tuning, optimizing, and deploying models on Intel hardware, enabling developers to achieve high performance with minimal effort.
Optimum-Intel leverages OpenVINO's inference optimization capabilities, such as quantization and graph transformations, to reduce model size and latency. By integrating with Hugging Face's ecosystem, users can easily convert and optimize models from the Transformers library for Intel CPUs, GPUs, and other accelerators.
The key benefit is seamless deployment: models optimized with Optimum-Intel can be loaded directly into OpenVINO GenAI, which provides a unified runtime for inference. This eliminates the need for manual conversion steps, making it easier for developers to bring AI applications to production.
Intel emphasizes that this solution is particularly useful for applications requiring efficient inference on edge devices, such as natural language processing and computer vision tasks. The support for popular frameworks like PyTorch and TensorFlow further broadens its appeal.
In summary, Optimum-Intel and OpenVINO GenAI offer a streamlined workflow for developers looking to optimize and deploy AI models on Intel architecture, reducing development time and improving performance.