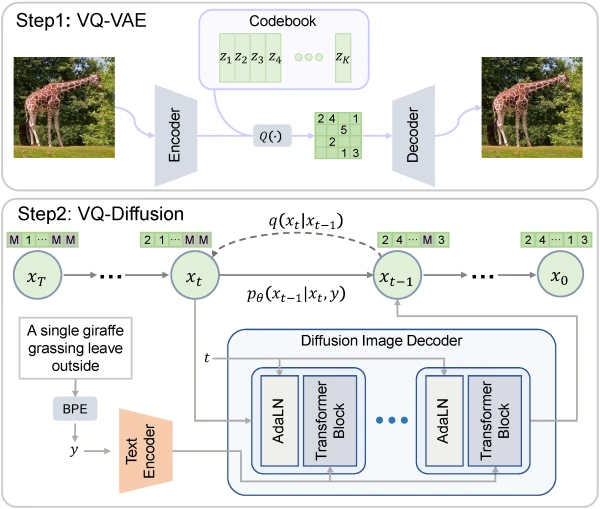
VQ-Diffusion is a conditional latent diffusion model developed by researchers at the University of Science and Technology of China and Microsoft. Unlike most diffusion models that operate on continuous noise, VQ-Diffusion works on a discrete set of vectors, offering a fresh perspective on image generation.
Demo
With the 🧨 Diffusers library, you can run VQ-Diffusion with just a few lines of code.
from diffusers import VQDiffusionPipeline
pipe = VQDiffusionPipeline.from_pretrained("microsoft/vq-diffusion-ithq")
pipe.to("cuda")
prompt = "A teddy bear playing in the pool."
image = pipe(prompt).images[0]
Architecture
VQ-Diffusion uses a VQ-VAE to encode images into discrete tokens. The forward diffusion process gradually adds noise by transitioning tokens between states: staying unchanged, resampling uniformly, or masking. An encoder-decoder transformer approximates the reverse process, predicting the original clean tokens conditioned on a text prompt.
Context
VQ-Diffusion stands out from continuous diffusion models by predicting the distribution of original tokens directly, rather than estimating added noise. Compared to autoregressive models, it avoids linear inference slowdowns with resolution, error accumulation, and directional bias, making it both efficient and robust.
Further Steps
Explore VQ-Diffusion with Hugging Face's Diffusers library for more experiments and applications.